
AI is hot right now. Since the launch of ChatGPT in early 2023, more and more professionals have been integrating AI tools into their day-to-day workflows. But are they using it in ethical ways? Ethical use of AI is important for everyone, but especially nonprofits, who try to hold themselves to higher standards.
AI tools vary widely, from simple meeting schedulers to complex language learning models, like ChatGPT. To that end, before unpacking the ethics of AI, let’s talk about what we mean by “AI” today.
Types of AI
The “highest” level of AI would be general intelligence — computers that can actually think — like in Ex Machina or Terminator. We are a long way off from that. Today, when we talk about AI, we are generally referring to software that extrapolates on what humans have already built and expands on that through routine statistical computations and probabilities to produce a result that can seem quite human. These types of AI fall into two basic categories: Machine Learning and Large Language Models.
One of the most common types of AI is Machine Learning Models. Machine Learning Models are built from a smaller set of attributes, not always publicly available, that are curated to produce an output for a very specific purpose. Many modern coding tools help software engineers build and refine code blocks. Some industries use information from existing customers to produce content such as a predictive risk score or likelihood score. When Netflix suggests what movies you might like, it is basing that on what movies you have already watched. TikTok knows what you like because it gathers information from the way you interact with it. These are all powered by machine learning algorithms. Machine learning is most often used for task-automation or creating a specific smaller data point, such as finding calendar blocks that are open for all attendees or creating a “score” for how likely you might watch a new show on your favorite streaming service.
Then there are Large Language Models (LLM), such as generative AI tools like ChatGPT. These models are built off of public information that is readily available. They use public data from all over the internet to see which words and phrases tend to correlate with each other the most. These are the most advanced tools, capable of performing the most complex, and seemingly “intelligent,” tasks. ChatGPT can write a speech, outline a presentation, and even write code. However, it is again important to remember that its outputs depend on its inputs. As noted above, machine learning models also help developers write code. Generative AI is a more advanced version of that. Generative AI tends to be used more for creation, such as creating a resume based on your listed experiences or asking DALL-E to create an image you need for a slide deck.
Despite their differences, both types of AI follow the same basic rules: using a large data set to identify and/or predict an outcome based on inputs and criteria provided by the user.
Bias in AI
Because AI draws from human input and human experiences, it can contain human biases. Our biases not only exist in the attitudes we carry but also in what we create. The things we build can inherit those qualities that we pass on to it. For example, we humans often exhibit selection bias, which is when we view information with a preconceived notion of what information matters. We tend to give greater weight to evidence that supports what we already believe. The flip side of that can be group attrition bias. When software developers feed data to AI models, they can exclude outliers, dropping out certain individuals or parts in a sample that do not conform to the rest of the individuals in that group. As a result, the AI can end up favoring the majority. For example, here is what turned up when we asked DALL-E to show us a picture of a doctor: 75% white, 0% women. In reality, we know that approximately 40% of doctors are women, and more are POCs.
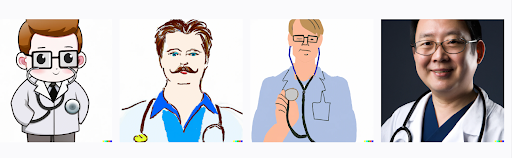
Another common form of bias in especially Large Language Models is availability bias. This form of bias generally states that a model will conform to the data that is generally available to it in the public domain. Think of a large scale Generative AI model, or your favorite search engine. It is going to produce results from whatever is most common or held by the majority in the public discourse. This poses problems when considering the use of language that is not common or always available in the public domain, such as the use of non-Western language or vernacular, or the representation of indigenous languages. If relevant information is not in the public domain, it will be excluded. To put it simply, Large Language Models don’t know what they don’t know, and therefore they can reinforce already existing power imbalances in society.
Applications
Let’s discuss an example: as a nonprofit organization, you would like to leverage AI to identify a diverse set of donors that can speak to the constituency that you serve — families from underrepresented backgrounds. You employ a model that identifies primary donors at large but does not acknowledge race/ethnicity or gender in its identification model. As such, it returns a set of donors that are available to you — all white and male. Why? The majority of donors for this model likely searched based on past contributions, capital, and history of giving, while ignoring primary factors that could contribute toward, and help to ensure, your donors are representative of the people that you serve. On the other hand, if you use a model that takes into account factors like race, ethnicity, and gender, you will get a much more diverse set of donors, but your employees, volunteers, and other stakeholders may have conflicted responses about the idea of targeting individuals based on things like race.
It’s a complicated ethical question, but it is important to know the implications. At the end of the day, is one “better” than the other? Is it the company’s fault for making such a model? The fact is that this model is just extrapolating and compounding on the inputs provided. In Machine Learning Models, it is possible to have some say in what data goes in and what is important, but this is virtually impossible in Large Language Models. There are just too many layers, data points, and coefficients (i.e. weights) to different factors.
Recommendations
We recommend making a few primary considerations when selecting models and tools. Bias happens more often when AI is used for creative purposes. Therefore, keep your work with generative AI confined to topics where there is a broad base of public information. Furthermore, fact check the results (like we did with the images of doctors). Generative AI can sometimes just make things up. It is important to train your workforce, including key stakeholders and volunteers, on the inputs and outputs of AI and the importance of interpreting those results within the context of human reason.
For information that is not available to the public, and that concerns predictive or model generation, there are two primary considerations when selecting such models or tools: 1) Is the Data Scientist(s) supporting this model trained on Diversity, Equity and Inclusion and 2) What say do you have over the creation/generation of the model? Specifically, for the latter question, it is always helpful to know which variables, or demographic factors, have more dominant weight on the results of the model. Whatever company you work with needs to be transparent about those things. Also, you should be transparent with your stakeholders about the demographic data you are looking for. You might consider holding a workshop or listening session that addresses the potential ethical pros and cons of AI specific to your organization.
Conclusion
In sum, Machine Learning tools that handle simple tasks, suggesting meeting times, are not concerning. Models that involve demographic considerations need to be transparent about the factors involved and the weights they are given. Nonprofits should also be transparent with their stakeholders about how and why they are using such tools. For generative AI, train your staff and volunteers to only use it when there is a lot of publicly available information about the topic, and always fact check the results. Remember, AI reflects our biases. Being aware of those biases and being intentional about including historically marginalized voices in your decision making processes can go a long way toward ensuring that you use these exciting new tools responsibly.
we can help you protect the people you serve!


Mike Baker
Mike is a Consultant at Undaunted Consulting. He specializes in data visualization, dashboarding, and generative AI solutions. He works hard to help nonprofits make a greater impact, and he's passionate about family support, DEI, and education.
